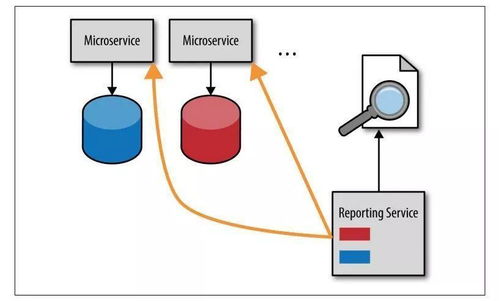
HCIP學習筆記 數據庫服務規劃之五——數據處理服務
在HCIP(Huawei Certified ICT Professional)認證的數據庫服務規劃知識體系中,數據處理服務是構建高效、可靠數據平臺的核心環節。它不僅是數據存儲的延伸,更是實現數據價值轉化、支撐業務智能決策的關鍵。本篇筆記將聚焦數據處理服務的核心組件、規劃要點及華為云相關實踐。
一、 數據處理服務的定義與價值
數據處理服務泛指對存儲在數據庫中的數據執行的一系列操作,旨在將原始數據轉化為對業務有用的信息、知識或決策依據。其核心價值在于:
- 數據價值提煉:通過清洗、轉換、聚合、分析等操作,從海量數據中提取出有意義的模式、趨勢和洞察。
- 業務敏捷響應:高效的數據處理能力能夠支撐實時或準實時的數據分析需求,助力業務快速響應市場變化。
- 降低決策成本:自動化、智能化的數據處理流程可以減少人工干預,提高決策的準確性和效率。
二、 核心服務組件與規劃要點
一個完整的數據處理服務規劃通常涵蓋以下關鍵組件,每個組件都有其特定的規劃考量:
- 批量數據處理:
- 典型場景:離線報表生成、歷史數據歸檔、大規模數據清洗與轉換(ETL)。
- 規劃要點:
- 計算資源:根據數據量、處理復雜度(如關聯、聚合)和SLA(服務等級協議)要求,規劃足夠的計算資源(如Spark on YARN集群規模)。
- 調度策略:設計合理的作業調度策略(如依賴調度、周期調度),避免資源沖突,優化整體處理流程。
- 數據分區與存儲:結合數據湖(如OBS)或數據倉庫,設計高效的數據分區策略,提升I/O性能。
- 流式數據處理:
- 典型場景:實時監控、實時推薦、欺詐檢測、物聯網(IoT)數據實時分析。
- 規劃要點:
- 延遲與吞吐:明確業務對處理延遲(如毫秒級、秒級)和吞吐量(如每秒事件數)的要求。
- 容錯與狀態管理:規劃檢查點(Checkpoint)機制和狀態后端存儲,確保Exactly-Once或At-Least-Once語義,保障流處理作業的容錯性。
- 源與匯的對接:規劃好與消息隊列(如Kafka)、數據庫、數據湖等數據源和數據目的地的穩定連接。
- 交互式查詢與分析:
- 典型場景:即席查詢(Ad-hoc Query)、多維分析(OLAP)、數據探索。
- 規劃要點:
- 查詢引擎選擇:根據數據規模、查詢模式和并發需求,選擇合適的查詢引擎(如Presto, Impala,或華為云的DWS的交互式分析能力)。
- 緩存策略:規劃結果集緩存或中間數據緩存,加速高頻、重復查詢。
- 資源隔離:為不同業務部門或優先級的查詢任務規劃資源隊列(Queue),避免相互干擾。
- 數據挖掘與機器學習:
- 典型場景:用戶畫像、銷量預測、智能風控。
- 規劃要點:
- 數據準備:確保有高質量、標注清晰的訓練數據集,并規劃好特征工程的處理流程。
- 算力與框架:根據模型復雜度選擇適當的計算框架(如Spark MLlib, TensorFlow)和GPU/CPU資源。
- 模型管理與部署:規劃模型的版本管理、評估和在線/離線部署流程。
三、 華為云相關服務與實踐建議
在華為云生態中,數據處理服務通常由多個云服務協同完成,規劃時需要整體考慮:
- 批量處理:數據湖探索(DLI) 提供全托管的Spark和Flink服務,是進行大規模批處理和流處理的理想選擇。規劃時需關注隊列的CU(計算單元)配置與彈性伸縮策略。
- 流處理:DLI的Flink作業 或 云數據遷移(CDM) 結合 數據倉庫服務(DWS) 的實時入庫能力,可構建端到端的流處理管道。
- 交互式分析:數據倉庫服務(DWS) 本身具備強大的MPP并行分析能力,適用于復雜的交互式查詢。對于更輕量的即席查詢,可結合 DLI 對OBS中數據的查詢能力。
- AI與機器學習:ModelArts 平臺提供了從數據標注、模型訓練到模型部署的全流程能力,可與DLI、DWS等數據源無縫集成。
規劃實踐建議:
1. 以業務需求為驅動:始終從業務場景(如“需要多快看到結果?”“分析的數據量有多大?”)出發,倒推技術選型和資源配置。
2. 考慮數據生命周期:將數據處理流程與數據的產生、存儲、歸檔、銷毀的全生命周期管理相結合。
3. 注重成本與性能平衡:利用云服務的彈性,在業務高峰時自動擴容,低谷時自動縮容,優化成本。例如,DLI的按CU時計費模式。
4. 確保安全與合規:在數據處理各環節規劃數據加密、訪問控制、審計日志等安全措施。
###
數據處理服務是數據庫服務規劃中承上啟下的關鍵一環。成功的規劃要求我們深入理解各類處理范式(批、流、交互、AI)的技術特點,緊密結合華為云提供的豐富PaaS服務,并以滿足業務價值為目標,設計出彈性、高效、安全的數據處理架構。在實際工作中,需要持續監控和優化處理任務的性能與成本,使數據真正成為驅動業務的核心資產。
如若轉載,請注明出處:http://www.jcardcn.com/product/9.html
更新時間:2026-05-18 18:29:13